The Action panel always provides space for at least one set of search terms: the search terms used by the main part of the action. The action panel may provide space for four other sets of search terms used by four other parts of the action: “filter files”, “file sectioning”, “extra processing”, and “context”. How many of those are available depends on whether your chosen action type uses those parts, and whether you’ve selected an option for those parts that requires the part to use a search term. If you set “file sectioning” to “line by line”, for example, then the “file sectioning” part of the action doesn’t need any search terms. It does when you set it to “search for sections”. If you turn on “extra processing” that part requires one or more search-and-replace pairs. If you turn off “extra processing”, that part doesn’t show anything but its checkbox.
PowerGREP can search for four kinds of items:
Most of the time you will be working with regular expressions. They allow you to specify the form of the text or data you want to search for, rather than entering the exact text or data you want to find. By using regular expressions, you can unleash PowerGREP’s full potential. Automating search or text processing tasks using PowerGREP and regular expressions will save you a lot of time and tedious work.
If you are new to regular expressions, the regular expression tutorial in this help file will teach you everything you need to know. Given an hour or two of practice, you will soon be up to speed.
You probably also want to have a look at RegexBuddy and RegexMagic. Both products are available separately. RegexBuddy makes it much easier to work with the regular expression syntax to create and edit regular expressions for use with PowerGREP and a variety of other tools and programming languages. While editing a regular expression in PowerGREP, simply click the RegexBuddy button in the Action toolbar to edit it with RegexBuddy. RegexMagic allows you to generate regular expressions without dealing with the regular expression syntax at all. RegexMagic supports all popular regular expression flavors, including the one used by PowerGREP. Simply click the RegexMagic button in the Action toolbar to invoke RegexMagic to generate a regular expression.
All four search types allow you to use match placeholders and path placeholders. Match placeholders allow you to insert search matches and search match numbers. Path placeholders are substituted with various parts of the name and path of the file being searched through. Use them to search for and/or to create file references. You can disable placeholders in the action & results preferences if they conflict with text you’re searching for.
Examples: Add line numbers, Collect page numbers and Update copyright years
The search items can be entered in three ways. For free-spacing regular expressions, only the “single item” and “list” entry methods are available. The other three kinds of search items support all three entry methods.
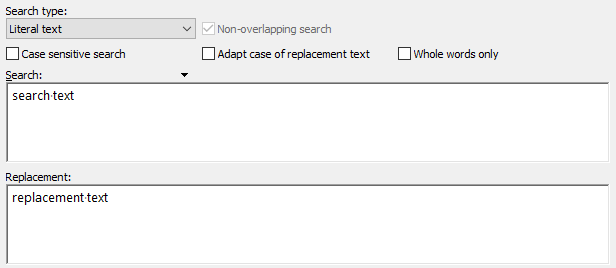
Single item: Enter just one literal piece of text, one regular expression, or one chunk of binary data. PowerGREP will give you one edit box for the search text, and one edit box for the replacement text or the text to be collected (if any).
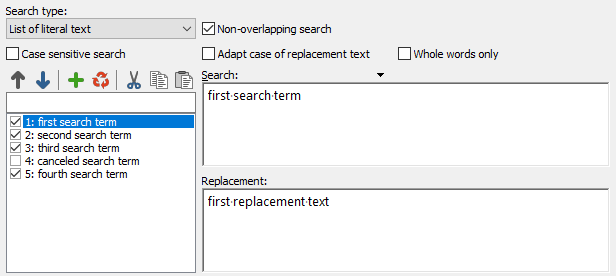
List: Enter multiple items, one by one. PowerGREP will give you one edit box for the search text, and one for the replacement or collection text, plus a list to add, remove and rearrange the items. Each item in the list will have a check box. Clear the check box to disable the item without deleting it from the list. This can help you experiment with different alternatives.
Example: Boolean operators “and” and “or”
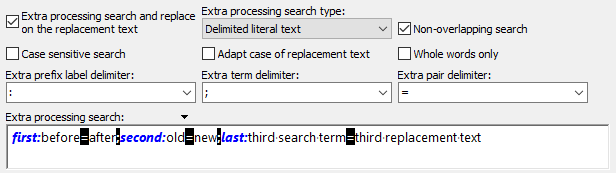
Delimited: PowerGREP will give you one edit box to enter multiple search terms, or multiple search-and-replace or search-and-collect pairs. This way of entering the search terms is most convenient if you already have them in some sort of delimited format. You can copy and paste them into the edit box. If the search terms are stored in a delimited text file, you can right-click on the box and select Insert File in the context menu to load the search terms from the file.
The search prefix label delimiter is optional. If you specify one, you can use it to prefix search search term with a descriptive label. The search item delimiter delimits search terms, or search-and-replace or search-and-collect pairs. The search pair delimiter separates each search term from its substitution.
All three delimiters must be unique. You can use any sequence of characters that does not occur in any of the regular expressions or replacement texts you’ll be working with.
Example: Collect XML Data with entities replaced
Several action parts such as “extra processing” or the main part of the action expect a replacement text or a text to be collected for each search term. When the search type is a regular expression, you can use backreferences to capturing groups to reinsert part of the regex match into the replacement or the text to be collected. Regardless of the search type you can also use match placeholders to reinsert the search match and path placeholders to insert parts of the path of the file being searched through.
The “non-overlapping search” option is only available for search term lists, and delimited search terms. It is on by default. Turning it on or off can have a major effect on the search results.
With non-overlapping search enabled, PowerGREP will search through the text only once, looking for all search terms at the same time. Two search matches can never overlap. With non-overlapping search disabled, PowerGREP will search through the text as many times as you provided search terms. The same part of the text can be matched by more than one search term, causing those matches to overlap. Obviously, searching through the text multiple times takes longer than searching it only once.
Non-overlapping search works differently for literal text or binary data than it does for regular expressions. Suppose you are searching through one file containing the text The category for "cat" and "bobcat" is "mammal". You entered the literal text search terms cat, category and bc. For literal text, the order of the search terms doesn’t matter. Executing this search finds each of the 3 terms once. When doing a literal text search, PowerGREP scans the file one character after the other. At each character position it evaluates the entire list of search terms. If more than one term matches, PowerGREP chooses the longest one. That is why the word category in our sample is matched by the search term category instead of cat even though both could be matched. When a match is found, PowerGREP continues the search after the match. Each character can be part of only one search match. That is why cat does match the second syllable in bobcat in our example. When bc is matched, PowerGREP continues the search starting with the a in bobcat. At that point none of the search terms can be matched in the remainder of the file.
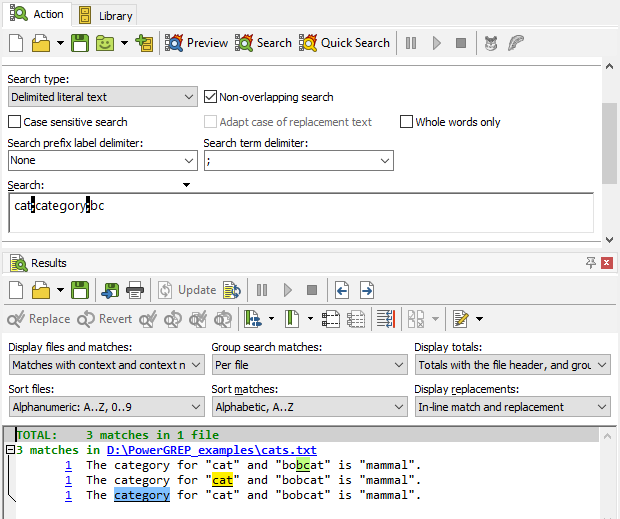
When searching for a list of regular expressions, the order of the search terms does matter. Note that merely setting the “search type” to “regular expression” is not enough to trigger this difference. If you select “regular expression” but then type in pure literal text, PowerGREP runs a literal text search. So we change our example to search for the regular expressions cat+, category+, and bc+. Executing this search finds cat twice and bc once. The regex category+ finds no matches at all. PowerGREP scans the file one character after the other as for a literal text search. But this time it tries the regular expressions one after the other. As soon as one regex matches, the match is accepted. The other regexes are not tried at the same character position, even if one of them might find a longer match. As soon as PowerGREP finds cat at the start of the word category, it accepts the match. The search then continues with egory, and category+ can no longer match.
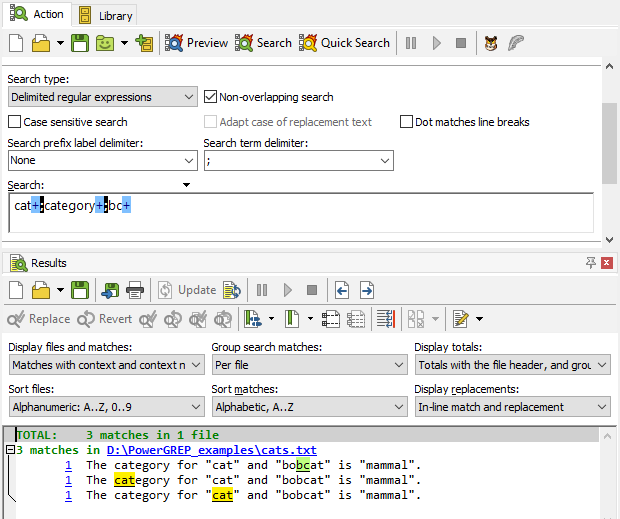
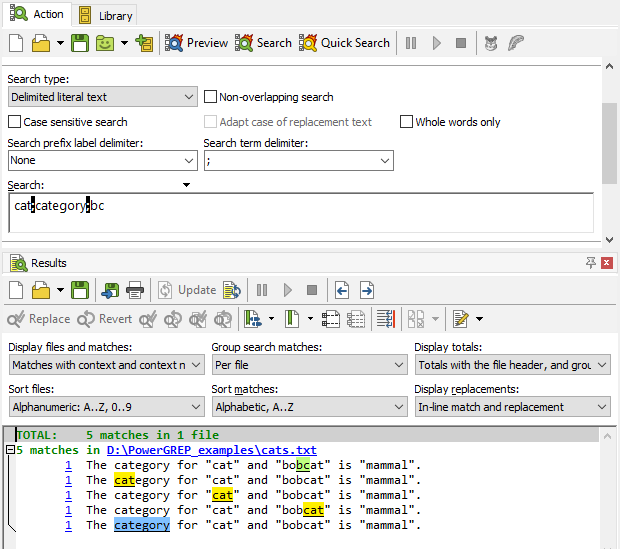
If you turn off the non-overlapping option, there is no difference between using literal text or regular expressions. PowerGREP scans the whole file once for each search term. Because each search term is handled separately, the matches of different terms can overlap. Using the same example text with either the 3 literal words or the 3 regular expressions yields the same results: cat is matched three times, category is matched once, and bc is also matched once. The first match of cat overlaps entirely with the sole match of category and the third match of cat overlaps partially with the match of bc.
To make all five matches clearly visible in the results, the “sort matches” option on the Results panel was set to “alphabetically”. If you set it to “original order”, PowerGREP shows the line of text only once with all five matches highlighted, making them difficult to distinguish.
In a search-and-replace action or extra processing search-and-replace, turning off non-overlapping search has an additional effect. The second search-and-replace in the list is not performed on the original text, but on the text as modified by the first search-and-replace. The third search-and-replace works on the results of the second, and so on. If the original text is The classification for "cat" is "mammal"., and your first search-and-replace pair is classification=category, and your second pair is cat=dog, the end result will be The dogegory for "dog" is "mammal".. The first iteration replaced classification with category, and the second replaced the first three letters of category with dog.
This last example executed as a non-overlapping search would yield The category for "dog" is mammal. After replacing classification with category, PowerGREP only searches through the remainder of the text for "cat" is "mammal"..
Though in this example, “dogegory” is not the result we wanted, in other situations the ability to have each search-and-replace pair work on the results of all previous pairs can be very useful, and result in some very powerful text processing.
Turn on “case sensitive search” if the difference between uppercase and lowercase letters your search terms matters. When on, cat matches only cat. When off, Cat, CAT and even cAt are also valid matches. Case sensitive searches are faster than case insensitive ones.
Turn on “adapt case of replacement text” to automatically give the replacement text or the text to be collected the same letter casing as the search match. Suppose you are searching for TWO cats and replacing with one DOG. You have “case sensitive” turned off and “adapt case of replacement text turned” on. The PowerGREP replaces two cats with one dog, Two cats with One dog, Two Cats with One Dog, and TWO CATS with ONE DOG. PowerGREP adapts all lowercase, all uppercase, title case, and first uppercase only. A match with any other combination of uppercase and lowercase letters is replaced with the replacement text as you entered it. So TWO cats, two CATS, and TwO CaTs are all replaced with one DOG as you entered it.
Turn on “whole words only” to match only complete words. With this option on, searching for cat does not match the first three letters in category.
What “whole words only” really does is check if the match is not immediately preceded and not immediately followed by a character that could be part of a word. cat fails category because of the e immediately after the potential match. Note that your search term must be a word or phrase. If your search term does not start with a character that can occur in a word, PowerGREP will not find any matches at all when you turn on “whole words only”.
The option “dot matches newlines” controls the behavior of the dot in a regular expression. By default, the dot will match any character except the line break characters CR (carriage return), LF (line feed), VT (vertical tab) and FF (form feed). When you turn on “dot matches newlines”, the dot will match any character including line break characters.
When using a list of search terms, the above options apply to all search terms. When using regular expressions, you can use mode modifiers to toggle the some of the options for individual regular expressions (or even parts of regular expressions). Put in front of a regular expression to make it case insensitive, or to make it case sensitive. Use to turn on “dot matches newline”, and to turn it off.