With the “file sectioning” part of the action definition, you can specify which parts of each file PowerGREP should process. You can make PowerGREP search through only part of each file, or split up each file any way you want, rather than searching the whole file at once. A common choice is to process files line by line. The “file sectioning” action part is available for all action types except “rename files or folders”.
![]()
The default is “do not section files”. PowerGREP searches the whole file without any boundaries. Search matches can span multiple lines, or even the entire file. Not sectioning files is the fastest option.
![]()
The “simple search” action type offers only two file sectioning options. Instead of the “file sectioning” drop-down list you get a “line by line” checkbox. Ticking the checkbox selects “line by line” file sectioning, while clearing the checkbox is the same as selecting “do not section files”.
When you select “line by line”, PowerGREP scans the file for line breaks. Each line is then searched through separately. The line breaks are not included in the sections. This means the search terms in the main part of the action can never match line breaks or span across lines. Traditional UNIX grep always applies your regular expression to one line at a time. The “line by line” option makes PowerGREP do the same.
If you tell PowerGREP to search through binary files and turn on “line by line” file sectioning then PowerGREP also scans binary files for line breaks and processes them line by line. Whether this is a good idea depends on the contents of your binary files and how many line breaks they have.
The line breaks between the lines are not part of the section when you select “line by line”. They are included when you select “line by line (including line breaks)”. The difference is important when replacing or collecting whole sections (see below). If the line break is included in the section, it will be deleted when the section is replaced, or included in the text to be collected.
When you tick the “line by line” checkbox, one or two additional checkboxes appear. The option “invert search results” makes the main part of the action match sections (lines) in which the search terms can not be found. The entire section (line) is then treated as the search match. That means that when collecting matches or replacing matches, whole sections (lines) are collected or replaced with a common replacement text.
When the action type is set to “list files”, the “invert search results” option appears even when file sectioning is disabled. The reason is that for “list files” action, this option applies to the whole file rather than just the section. When you turn on “invert search results” for a “list files” action, you get a list of all files in which the search terms cannot be found.
The option “list only sections matching all terms” appears if the main part of the action has more than one search term. Turn on this option to tell PowerGREP to retain only matches from sections (lines) in which all the search terms can be found. Search matches found in sections (lines) that contain only some of the search terms are discarded. If you turn on this option for a search-and-replace action, whole sections (lines) must be replaced with a common replacement text.
Example: Find two or more words on the same line

All other action types that support file sectioning provide additional options. The option “match whole sections only” limits search matches in the main part of the action to those that match an entire section. All other matches are skipped. When sectioning a file line by line, for example, only search matches spanning a complete line are retained.
“Collect whole sections”, “replace whole sections” , “delete whole sections” , or “split whole sections” causes the main part of the action to act as if the entire section matched a search term, even if the search term matches only part of the section. The whole section will be returned as the search result. The label of this option changes with the action type, but the core behavior remains the same. Actions that collect data will collect the whole section, search-and-replace actions replace the whole section, search-and-delete actions delete the whole section, and split actions write the whole section to the target file.
Examples: Extract or delete lines matching one or more search terms, Boolean operators “and” and “or” and Split web logs by date
Turn on to treat sections in which the search term cannot be found as search matches and to treat sections in which the search term can be found as not having matched.
If you turn on both "invert search results" and "match whole sections only" then sections which are matched only partially or not at all by the search term are treated as search matches.
If you turn on both "invert search results" and "list only sections matching all terms" then sections in which all terms can be found are treated as not having matched while sections in which none or some (but not all) search terms can be found are treated as having matched.
Turning on "invert search results" automatically turns on "collect/replace/delete/split whole sections" because when sections without search terms have to be treated as matches, the only way to do that is to treat the whole section as the match.
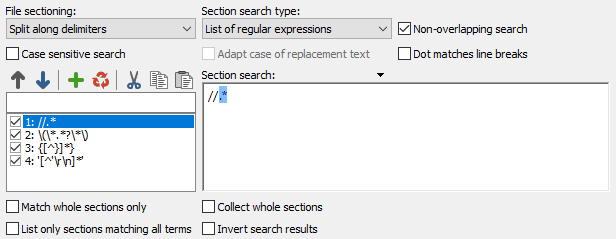
To split a file into chunks other than single lines, use the “split along delimiters” sectioning type. The two most common situations for splitting a file into sections are files with custom record delimiters (i.e. not line breaks), and files where you don’t want to search through part of the file.
Custom delimiters are easy. Simply enter the record delimiter the files use as the search term in the sectioning part. PowerGREP will first search for the delimiters, and then search through each section of the file (i.e. record) between delimiters, as well as the sections before the first delimiter and after the last delimiter. The delimiters themselves are never “seen” by the main part of the action.
Particularly powerful is the ability to specify which sections of the file you do not want to search through. E.g. if you want to process some source code, but don’t want to search through comments or strings in the source code, use the “split along delimiters” sectioning type, and enter a list of regular expressions matching comments and strings in the source code. The screen shot above shows comments (steps 1 to 3) and strings (step 4) used by the Delphi programming language. The result is that PowerGREP will treat comments and strings as “delimiters”, and only search through the sections of the file between comments and/or strings.
Examples: Search through or skip comments and strings, Add line numbers, Collect page numbers, Collect paragraphs (split along blank lines) and Put anchors around URLs that are not already inside a tag or anchor
To do things the other way around, i.e. specify the sections that you do want to search through, select the “search for sections” sectioning type. When executing the action, PowerGREP will first search for the sectioning search terms. The main part of the action is then restricted to the sections in the file matched by the sectioning search terms. Anything between the sections is ignored by the main action. E.g. the four regular expressions in the screen shot could be used to search through only comments and strings in Delphi source code.
The last sectioning type, “search and collect sections” is useful when you cannot easily create a regular expression that matches only the section of the file you want to search through. Though you can usually solve that problem with clever use of lookaround, collecting sections is often much easier and more straightforward.
When collecting sections, each sectioning step requires a “section collect”. The “section collect” must be a backreference to a numbered or named capturing group in the sectioning regular expression. The text matched by the capturing group is the section that will be searched through. You can specify only one capturing group per sectioning step. E.g. if you set “section search” to the regex <H[1-6]>(.*?)</H[1-6]> and the “section collect” to the backreference \1, the main action will process everything between heading tags in an HTML file, ignoring the heading tags themselves and everything outside heading tags.
If you leave the “section collect” empty for a particular sectioning step, that step’s matches will never be searched through. This can be useful in a non-overlapping search where you want to exclude some sections.
Examples: Search through or skip comments and strings, Make sections and their contents consistent and Replace HTML attributes
You can easily test the file sectioning settings by running a dummy search. Set the action type to “search”. Enter the regular expression .++ as the search term and turn on “dot matches newlines”. This regex will match each section entirely and display it in the results.
When you don’t section files, the main part of the action searches through the entire file. When you do section files, the main part of the action searches through the sections only. The main part of the action cannot “see” outside of the sections. This doesn’t matter when searching for literal text or binary data, but it does matter when searching using regular expressions.
As far as the regular expression engine is concerned, when it searches through a section, that section is all that exists. The start-of-file anchor \A and the end-of-file anchor \z will match at the start and the end of every section. Lookaround will not be able to “see” beyond the section.
As described in the topic discussing search terms, when the search terms consist of multiple items, an option “non-overlapping search” becomes available. What follows assumes you have already understood the implications of overlapping and non-overlapping searches described there.
This option is enabled by default. PowerGREP divides the file into sections only once and sections never overlap. In most situations, a non-overlapping search is what you need. E.g. when sectioning along comments and strings in a programming language, you want to ignore comment characters inside strings, and quote characters inside comments. A non-overlapping search automatically takes care of that.
When you turn off “non-overlapping search”, PowerGREP will section the file as many times as you provided sectioning search terms. The main action is run entirely on all the sections found by the first sectioning step, before PowerGREP continues with the second sectioning step.
This means that in a search and replace action, which modifies the file being searched through, the second sectioning step will process the file after all the sections found by the first sectioning step have been searched-and-replaced through completely. This means the second sectioning step may find sections differently than it would when processing the original file. Depending on what you’re doing, and whether you took this into account, this cascade effect may produce desirable or undesirable results. This applies even when the target types is set to make a copy of the file, and even when previewing the action. PowerGREP will modify the working copy of the file, regardless what happens with it in the end.
When using regular expressions, named capturing groups carry over from the file sectioning to both the main part of the action and the extra processing part. If the sectioning regex uses a capturing group, you can use a backreference to that capturing group in the regular expression and/or the replacement text of the main action and/or the extra processing.
Examples: Collect a list of header and item pairs and Make sections and their contents consistent